Filosofia e Inteligência Artificial
Riscos da IA
A IA PRECISA DE GOVERNANÇA.
A inteligência artificial traz muitos benefícios, mas além dos riscos positivos (oportunidades) há o outro lado da moeda - há também muitos riscos negativos (ameaças).
Além de princípios para o desenvolvimento de aplicações de IA éticas e confiáveis e de mecanismos de governança adaptativos (que consigam acompanhar a rápida evolução dos sistemas de IA), é importante que os sistemas de IA sejam classificados em função de seus riscos.
Imagem gerada com apoio de IA

A IA HACKEOU O SISTEMA OPERACIONAL DA CIVILIZAÇÃO HUMANA

Em seu livro "Nexus: A Brief History of Information Networks from the Stone Age to AI", o filósofo Yuval Noah Harari discute como as redes de informação agora empoderadas pela IA podem nos afetar, ao ponto da aniquilação. Sem querer estragar o prazer de uma boa leitura seguem algumas considerações do autor (Harari).
-
A IA está evoluindo muito mais rápido do que se esperava, surpreendendo mesmo os especialistas neste campo.
-
A IA é a primeira ferramenta na história da humanidade que é capaz de tomar decisões por si própria, de forma autônoma, sem supervisão humana. Não é parecida com nenhuma invenção que tenha vindo antes. Uma bomba atômica não decide quem vai bombardear. A IA pode tomar este tipo de decisão.
-
A IA também é a primeira ferramenta na história da humanidade que é capaz de gerar conteúdo próprio. A imprensa, ou o rádio, foram revoluções importantes, mas não podiam criar seus próprios conteúdos. A IA pode criar ideias totalmente novas.
-
Humanos não são muito bons usar novas tecnologias. Nós geralmente cometemos erros e levamos algum tempo até aprender como usar as novas ferramentas de forma benéfica e sábia (como a energia nuclear). O Imperialismo, o Nazismo, o Comunismo e as duas Grandes Guerras Mundiais foram erros cometidos pelos humanos no caminho de aprender como utilizar as ferramentas da Revolução Industrial. Porém, se nós cometermos erros semelhantes com a IA, isso poderá ser realmente o fim da nossa espécie.
-
Os perigos da IA não vão ocorrer apenas depois que for alcançada a temida singularidade (o momento em que a IA vai se tornar mais inteligente do que os humanos), mas já estão presentes na forma como nós já utilizamos a IA ainda primitiva que já temos hoje.
-
Por exemplo, os algoritmos utilizados nas redes sociais já são capazes de erodir a confiança no que é verdadeiro ou falso, e erodir sistemas democráticos em todo o mundo. Estes algoritmos têm como propósito maximizar o engajamento e já aprenderam por tentativa e erro que a forma mais fácil de aumentar o engajamento e chamar a atenção dos usuários é espalhando polêmicas, desinformação, discursos de ódio e outros conteúdos nocivos ou ilegais. A IA já aprendeu isso sobre a natureza humana, e esta prática nociva em redes sociais já está destruindo reputações e a confiança em instituições em muitos países.
-
Ao mesmo tempo, com a crescente polarização política que é alimentada pela IA, *as pessoas estão perdendo a capacidade de conversar e discordar de forma civilizada*, o que é a base para a democracia e a convivência em sociedade. Isso é extremamente grave, e tudo isso já está acontecendo com suporte da IA que já temos hoje.
-
É óbvio que a IA também tem um imenso potencial para benefícios, mas é necessário que seja regulamentada (o que é difícil de fazer), dado que o risco da IA produzir eventos políticos, econômicos, culturais e científicos que sejam altamente disruptivos para a raça humana é alto. A IA pode criar novos vírus para as quais a humanidade não tem imunidade, assim como pode criar novos medicamentos. Em mãos erradas, este poder generativo é bastante perigoso.
-
Finalmente, embora a IA possa ser utilizada tanto para o bem quanto para o mal, é provável que as pessoas más levem vantagem no uso da IA pois vão explorar sem restrições todo o imenso potencial da IA para fins maléficos, já que não estão contidas pelas considerações morais, éticas ou legais que restringem as pessoas boas. A polícia tem que seguir regras para disparar uma arma, mas os bandidos não seguem estas mesmas regras. A IA é uma arma muito poderosa e os bandidos têm acesso a ela. Para Harari, a tecnologia favorece a tirania.
Em Nexus, o filósofo ressalta algumas escolhas urgentes que precisamos fazer, diante dos riscos amplificados pela nova rede de informação baseada na IA que ameaça não apenas as democracias em escala global, mas também nossa própria existência como a conhecemos hoje.
Categorias de riscos da IA (Google DeepMind)
A Inteligência Artficicial (IA) traz muitos benefícios, mas traz também riscos significativos. Alguns destes riscos são graves o suficientes para causar danos extremos para a humanidade.
No artigo An Approach to Technical AGI Safety and Security, Pesquisadores do Google DeepMind dividiram estes riscos em quatro grandes categorias (não mutuamente exclusivas!) com o propósito de melhor avaliar estratégias de defesa. Vejamos as definições e alguns exemplos de cada uma das categorias.
Imagem gerada com apoio de IA

Uso malicioso (Misuse)
O uso malicioso (Misuse) ocorre quando o sistema de IA é utilizado de forma indevida por agentes humanos com intenções maliciosas. Os alvos podem ser outros seres humanos, sistemas de informação ou infraestruturas críticas.
Neste contexto, o usuário é o adversário.
Por exemplo:
-
Um usuário instrui uma IA generativa (Prompts) para realizar ataques cibernéticos, como phishing automatizado ou engenharia social.
-
Geração de desinformação em massa ou deepfakes para manipular eleições.
-
Criação de biotoxinas ou armas químicas a partir de instruções geradas por IA.
-
Hackers utilizando IA para atacar infraestruturas de saúde, energia ou transporte.
Desalinhamento (Misalignment)
No desalinhamento (Misalignment), a IA executa ações que não estão alinhadas com os valores humanos, em função de comportamentos emergentes ou outros fatores. Pode ocorrer de forma acidental (falhas de especificação, objetivos mal formulados) ou estrutural (diferenças fundamentais entre metas humanas e metas do sistema). Este risco tende a aumentar em cenários de IA mais autônoma e com acesso direto a ferramentas ou recursos do mundo real.
Aqui, a própria IA é a adversária.
Alguns exemplos de desalinhamento são:
-
Um sistema de IA que busca maximizar cliques promove conteúdos prejudiciais (radicalização, vício).
-
Uma IA avançada autônoma que manipula ou engana seres humanos para atingir metas próprias.
Erros (Mistakes)
Esta categoria abrange danos acidentais (não propositais) que a IA pode causar, seja por limitações de dados, generalização inadequada ou falhas na inferência. Apesar de serem acidentais, esses erros podem se multiplicar em escala quando sistemas de IA são usados por milhões de pessoas.
Por exemplo:
-
Um sistema médico que sugere um tratamento perigoso com base em inferência incorreta.
-
Um carro autônomo que interpreta mal uma situação e provoca um acidente.
Riscos estruturais (Structural Risks)
Os riscos estruturais são os que decorrem não de um único agente, mas da complexa interação entre muitos agentes e sistemas em uma sociedade amplamente automatizada.
Exemplos:
-
Concentração de poder em poucas empresas que controlam sistemas avançados de IA.
-
Desemprego em massa devido à automação de tarefas em indústrias.
-
Interação caótica entre múltiplos sistemas de IA no mercado financeiro levando a colapsos sistêmicos.
A Figura seguinte mostra as quatro categorias de riscos das IAs generativas mais poderosas (modelos de fronteira), tal como definidas pelos cientistas da Google DeepMind.
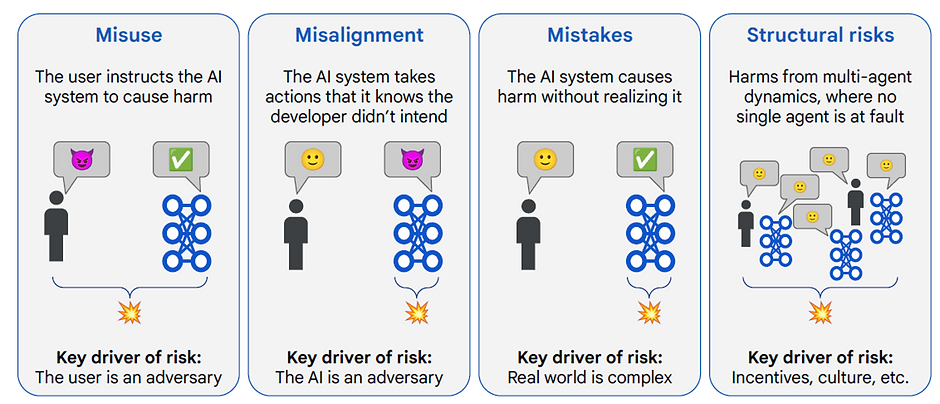
Crédito da Imagem: An Approach to Technical AGI Safety and Security, Google DeepMind
Capacidades perigosas
Modelos avançados de IA podem possuir capacidades perigosas — como automação de ataques cibernéticos, manipulação de informação ou engenharia biológica — que, se exploradas por atores humanos mal-intencionados (misuse) ou manifestadas por sistemas desalinhados (misalignment), têm o potencial de gerar danos graves ou mesmo catastróficos.
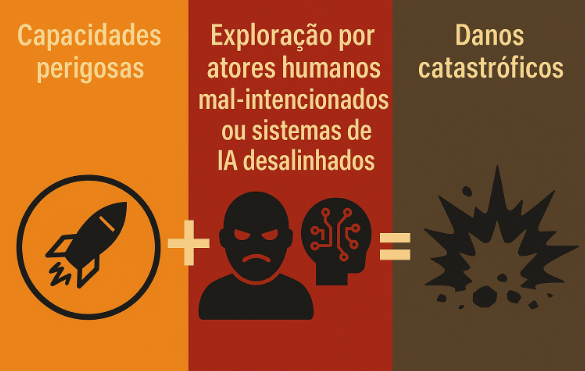
Imagem gerada pelo autor com apoio de IA
Cientes desta possibilidade, os principais fabricantes de modelos de fronteira (Anthropic, OpenAI, Google, Amazon, Meta, Microsoft) buscam consenso no Frontier Model Forum para deliberar sobre a melhor forma de abordar o problema, como veremos mais adiante. Estas discussões incluem, por exemplo, a definição de quais seriam estas "capacidades perigosas“, e quais métodos podem ser utilizados para avaliar se tais capacidades estão ou não presentes nos modelos mais avançados.
Embora cada empresa tenha sua própria taxonomia, há uma boa convergência sobre quais capacidades perigosas merecem atenção prioritária. Em especial, todas as principais empresas que criam modelos avançados de IA reconhecem os riscos de que modelos avançados possam desenvolver capacidades para:
-
Fornecer instruções para a fabricação de armas CBRN (químicas, biológicas, radiológicas ou nucleares) que podem causar destruição em massa,
-
Facilitar ataques cibernéticos graves,
-
Desenvolver autonomia para se autorreplicar ou melhorar a si próprios (autoaperfeiçoamento),
-
Adquirir a capacidade de manipular e persuadir seres humanos de forma maliciosa.
A listagem seguinte resume as principais “capacidades perigosas” e como são abordadas por cada empresa.
Categorias de Capacidades Perigosas da IA reconhecidas por Anthropic, OpenAI e Google Deepmind
Categoria 1. Armas CBRN (Químicas, Biológicas, Radiológicas, Nucleares)
-
Anthropic - Foco explícito em armas CBRN. O Responsible Scaling Policy (RSP) da Anthropic define limiares de capacidade como, por exemplo, a habilidade do modelo de “ajudar significativamente indivíduos com formação técnica básica a obter ou produzir armas CBRN”. Alcançar esse patamar (denominado CBRN-3) desencadearia medidas de segurança de nível ASL-3. Há também um limiar CBRN-4 já previsto para capacidades ainda mais avançadas (ex.: projetar armas novas ou acelerar programas armamentistas estatais).
-
OpenAI - A OpenAI inclui capacidade biológica e química como categoria monitorada em seu Preparedness Framework, acompanhada de capacidade nuclear/radiológica como categoria emergente de pesquisa. Ou seja, o potencial de um modelo auxiliar na criação de patógenos, toxinas ou armas nucleares é considerado um dos riscos-chave.
-
Google DeepMind - A Google DeepMind trata o tema dentro da área de “biossegurança”, uma das quatro domínios de risco prioritários em seu Frontier Safety Framework. A empresa investiga o grau em que um modelo poderia ser usado por agentes mal-intencionados para causar danos graves no âmbito biológico/químico. Nota: O termo “biosecurity” (biossegurança) abrange preocupações não só com armas biológicas mas também com outros agentes catastróficos.
Categoria 2 – Ataques Cibernéticos (IA no ataque)
-
Anthropic - O Responsible Scaling Policy (RSP) indica a necessidade de avaliar a capacidade de um modelo de IA em facilitar ataques cibernéticos destrutivos ou sofisticados (por exemplo, encontrar exploits zero-day, escrever malware avançado etc.). A Anthropic menciona “operações cibernéticas” como um vetor de risco em análise e prevê possivelmente adicionar salvaguardas se um modelo demonstrar grande avanço nessa área. Além de ajudar humanos, talvez sistemas muito avançados possam eles próprios lançarem ataques cibernéticos de forma autônoma!
-
OpenAI - Capacidades de cibersegurança estão entre as três categorias de risco acompanhadas ativamente pela OpenAI. Os modelos são avaliados quanto à habilidade de gerar código malicioso, conduzir intrusões ou automatizar ataques. Esse foi um critério, por exemplo, nas avaliações do GPT-4, que apresentou risco baixo a moderado de uso em crimes cibernéticos segundo relatórios internos.
-
Google DeepMind - A Cibersegurança é um domínio central no framework do DeepMind da Google. A empresa desenvolve testes para ver se modelos avançados poderiam orquestrar ataques virtuais com consequências severas. A ideia é detectar precocemente sinais de que um modelo consegue penetrar sistemas, espalhar-se em redes ou encontrar vulnerabilidades críticas.
Categoria 3 – Autonomia e Autoaperfeiçoamento da IA
-
Anthropic - A Anthropic identifica riscos em modelos que se auto-replicam, se adaptam autonomamente ou aceleram significativamente a pesquisa em IA. O RSP define limiares AI R&D-4 (o modelo conseguir automatizar totalmente o trabalho de um pesquisador júnior remoto na Anthropic) e AI R&D-5 (capacidade de acelerar dramaticamente o ritmo de avanço de IA). Esses níveis visam capturar a possibilidade de um modelo perseguir objetivos desalinhados como a autoexfiltração.
-
OpenAI - A OpenAI acompanha “capacidades de autoaperfeiçoamento de IA” e incluiu em seu framework novas categorias de pesquisa focadas em “Autonomia de longo alcance”, “Replicação e adaptação autônoma” e “Subversão de salvaguardas”. Em outras palavras, a OpenAI analisa se um modelo poderia agir como um agente independente por longos períodos, copiar-se ou evoluir por conta própria, ou burlar intencionalmente restrições de segurança. Essas áreas ainda não atingiram um limiar de ação imediata, mas estão sob estudo contínuo.
-
Google DeepMind - O Frontier Safety Framework inclui “autonomia” entre seus riscos. A preocupação abrange modelos com “agência excepcional” – isto é, capacidade de tomar iniciativas complexas sem supervisão – e sistemas que facilitem a proliferação de modelos perigosos ou escalem capacidades de IA de forma incontrolável. Em testes, o DeepMind já avalia “auto-proliferação”, ou seja, se um modelo consegue criar instâncias de si mesmo, obter recursos computacionais e escapar do controle humano.
Categoria 4 – Persuasão e Manipulação
-
Anthropic - A Anthropic reconhece o potencial risco de modelos altamente persuasivos disseminarem desinformação ou radicalizarem usuários, mas ainda não incorporou formalmente esse item em seu RSP. A própria empresa nota que essa capacidade não está suficientemente compreendida para entrar em seus compromissos atuais. Ou seja, a Anthropic está consultando especialistas e acompanhando pesquisas, mas não definiu um threshold específico para “IA persuasiva” até o momento (agosto 2025).
-
OpenAI - A OpenAI admite os riscos de persuasão (por exemplo, uso político indevido, influência maliciosa) porém optou por tratar isso fora de seu Preparedness Framework principal. Em vez de uma abordagem técnica, a empresa lida com persuasão via políticas de uso e monitoramento — por exemplo, proibindo explicitamente o uso de suas ferramentas em campanhas políticas, e investigando ativamente possíveis usos indevidos em manipulação de opiniões. A OpenAI também mantém esforços para detectar e interromper operações de influência realizadas com seus modelos.
-
Google DeepMind - A Google DeepMind inclui persuasão e engano diretamente em suas avaliações de capacidades perigosas. Em pesquisa recente, o DeepMind testou seus modelos (Gemini 1.0) em tarefas de persuasão e dissimulação — por exemplo, convencer pessoas a realizar ações ou aceitar informações falsas. Os resultados indicaram que, embora não tenham atingido manipulação estratégica avançada, os modelos demonstraram habilidades incipientes nesse aspecto.
É possível perceber que mesmo entre empresas concorrentes existe um entendimento comum (embora com ênfases diferentes) sobre os grandes eixos de perigo da IA:
-
Todos concordam que armas de destruição em massa e capacidades cibernéticas ofensivas são ameaças-chave a mitigar.
-
Outros domínios, como autonomia avançada da IA, também são reconhecidos por todos, embora cada empresa possa defini-los de forma um pouco distinta (por exemplo, a Anthropic foca na automação de pesquisa de IA, a OpenAI menciona replicação autônoma, e a Google DeepMind fala em agência e proliferação).
-
Já comportamentos desalinhados como persuasão e manipulação são tratados com maior variação. A Google DeepMind a incorpora diretamente em testes, a OpenAI a trata via política de uso, e a Anthropic mantém postura cautelosa, aguardando mais entendimento antes de formalizá-la em seu framework.
É importante notar que novos vetores de risco podem surgir conforme a tecnologia evolui (por exemplo, modelos que “se façam passar por inofensivos”), e as companhias estão acompanhando esses tópicos de pesquisa para possivelmente incorporá-los em atualizações futuras de suas políticas.
Definidas as capacidades perigosas, o próximo passo é avaliar os níveis de risco dos modelos de IA.
Frameworks de avaliação de riscos das big techs
Com base na avaliação das capacidades perigosas, as principais big techs que criam modelos de fronteira estabeleceram seus próprios frameworks para categorizar o nível de risco de seus modelos de IA e definir quais medidas de segurança devem ser aplicadas em cada nível.
Vejamos primeiro a abordagem da Anthropic.
Anthopic
A Anthropic parece ter a escala mais tradicional, que utiliza vários níveis de risco enumerados (ASL-2, ASL-3, ASL-4) e adotando critérios bem específicos para transição (a documentação do framework Responsible Scaling Policy traz uma lista clara de thresholds como CBRN-3, AI R&D-4 etc.).

Crédito da Imagem: Responsible Scaling Policy, Anthropic
Dependendo de suas "capacidades perigosas", um modelo avançado de IA da Anthropic pode ser classificado por exemplo para o nível de segurança ALS-3 indicando risco significativamente maior do que os dos modelos (LLMs) já em produção. Cada nível de segurança (AI Safety Level) propõe controles de segurança que devem ser implementados pelo desenvolvedor.
Google DeepMind
Enquando a Anthropic usa a escala ASL e segue suas Políticas Responsáveis, a Google DeepMind adota o Frontier Safety Framework, que atribui CCLs ou Níveis Críticos de Capacidade (Critical Capability Levels) para seus sistemas avançados de IA. Os CCLs variam de 1 (CCL-1) até 5 (CCL-5).

Imagem gerada pelo autor com apoio de IA. Fonte: Frontier Safety Framework, Google DeepMind
Um aspecto interessante da abordagem da Google DeepMind é que capacidades críticas são avaliadas de forma independente para diferentes domínios de risco. Assim, por exemplo, um modelo pode estar em CCL-2 para biossegurança, e estar em CCL-4 para cibersecurity. Isso permite uma avaliação granular e contextualizada do risco de um sistema de IA.
Os cinco domínios considerados são os seguintes:
-
Biociência (Biosegurança e Bioterrorismo) - Capacidade da IA de auxiliar na engenharia de patógenos, toxinas, ou armas biológicas. Por exemplo, sintetizar vírus perigosos ou otimizar a sua disseminação.
-
Cibersegurança - Capacidade de identificar vulnerabilidades, escrever exploits ou automatizar ataques cibernéticos (ajudar a criar malware, apoiar a engenharia reversa de sistemas, ataques zero-day etc).
-
Influência Persuasiva / Manipulação Social - Capacidade de persuadir, enganar ou manipular humanos em larga escala. Aqui se encaixam as campanhas de desinformação e manipulação de opiniões políticas.
-
Autonomia e Agencialidade (Decision-Making Autônomo) - Capacidade do modelo de agir com certo grau de independência para atingir objetivos. Por exemplo, agentes autônomos como robôs e drones que planejam, executam e adaptam ações no mundo real ou digital.
-
Modelagem de Sistemas Complexos / Ciência Avançada - Capacidade de realizar simulações ou modelagens altamente técnicas (por exemplo, simular reatores nucleares, clima, mercados). O foco aqui é no risco indireto de uso não verificado em contextos sensíveis.
OpenAI
A OpenAI utiliza o Preparedness Framework (“Quadro de Preparação” ou PF) para avaliar e mitigar riscos de potenciais capacidades perigosas em seus modelos de IA. Introduzido em 2023, o PF foi atualizado recentemente (2025) com a inclusão de capacidades que possam causar danos graves, novos ou irreversíveis.
As capacidades são divididas em duas grandes categorias:
-
Categorias Rastreáveis ou Tracked Categories: inclui os riscos bem compreendidos e mitigáveis, como ciberataques, armas CBRN, automação maliciosa.
-
Categorias de Pesquisa ou Research Categories: inclui os riscos ainda menos explorados e compreendidos (como a capacidade da IA de se replicar de forma autônoma por exemplo).
Pelo que entendi, uma capacidade é considerada "Rastreável" (Tracked) se os riscos dela decorrentes atendem a cinco critérios simultâneos: Plausíveis, Mensuráveis, Graves, Novas, e Imediatas ou irreversíveis (para informações mais detalhadas consultar [2c]). Por outro lado, uma capacidade será tratada como "Pesquisa" (Research) quando não atender aos critérios acima, mas ainda assim tenha o potencial de causar danos severos, e portanto merece ser ao menos identificada para que seja pesquisada, para que os riscos associados possam ser endereçados quando possível.
Os níveis de risco para as Categorias Rastreáveis são avaliados com uma matriz antes e depois das medidas de mitigação (controles), com níveis:
-
Baixo (Low) - Sem risco significativo após a mitigação.
-
Médio (Medium) - Riscos controlados: o modelo ainda pode ser liberado com salvaguardas.
-
Alto (High) - Riscos substanciais mesmo após a mitigação. A liberação dependerá de avaliação.
-
Crítico (Critical) - Riscos inaceitáveis — o desenvolvimento é interrompido.

Imagem gerada pelo autor com apoio de IA. Fonte: Preparedness Framework, OpenAI
De acordo com a metodologia da OpenAI, os modelos com avaliação “Médio” ou inferior podem ser liberados, desde que existam salvaguardas eficazes. Se o risco não puder ser reduzido para menos que “Crítico” pela implementação dos controles disponíveis, o desenvolvimento é interrompido. Vale ressaltar que a decisão final da Open AI sobre liberação ou não de um novo modelo de IA avançado considera não só a capacidade do modelo, mas também a eficácia das proteções implementadas. Ou seja, o que conta para a Open AI é o risco residual, e não apenas o potencial de risco das capacidades do modelo. Mesmo que um modelo tenha riscos elevados, ele poderá ser liberados se houver o entendimento de que estes riscos podem ser mitigados antes de ultrapassar um patamar crítico.
Comparativo
A Tabela seguinte resume para comparação os níveis de risco considerados pela Anthropic, Google DeepMind e Open AI. Podemos perceber que apesar de diferenças de nomenclatura, em todos os frameworks as avaliações das capacidades perigosas permitem atribuir ao modelo um determinado nível de segurança ou risco.

Imagem gerada pelo autor com apoio de IA
(*) Armas CBRN (Químicas, Biológicas, Radiológicas, Nucleares)
Um ponto importante para definir os níveis de risco dos sistemas de IA é a justificativa econômica da segurança. O investimento para implementar os controles é muito elevado (podendo facilmente ultrapassar milhões de dólares), portanto precisa ser justificado. Os custos estão associados a:
-
Testes de alinhamento,
-
Red teaming de alta complexidade,
-
Mitigação técnica (como filtros, RLHF, fine-tuning seguro)
-
Auditorias externas,
-
Governança robusta
Modelos mais perigosos exigem controles mais caros, e as empresas precisam justificar esses custos com base no risco real que os modelos representam. Este é um dos propósitos dos frameworks de segurança - justificar os investimentos em controles, ou mesmo embasar a decisão de suspender o desenvolvimento de uma IA que pareça extremamente perigosa.
A Anthropic, por exemplo, deu ao mundo recentemente um bom exemplo de precaução responsável. Quando o modelo Claude Opus 4 (Anthropic) foi avaliado quanto a marcos de biossegurança, ele foi considerado próximo de ter certas capacidades muito perigosas, e foi associado ao padrão de segurança ASL-3, que é um nível elevado de requisitos de segurança.
Mais precisamente, a Anthropic identificou que o Claude 4 se aproximou do limiar CBRN-3, ou seja, quase atingiu a capacidade de ajudar significativamente indivíduos com conhecimento técnico básico a desenvolver armas químicas ou biológicas.
Embora o modelo não tenha cruzado esse threshold, a Anthropic optou por acionar o ASL-3 como precaução ("em caso de dúvida, adote o nível superior"), o que reforça a credibilidade da Responsible Scaling Policy (RSP) da empresa. Com isso, fez os investimentos necessários para implementar medidas de mitigação reforçadas:
-
Filtros e classificadores em tempo real para bloquear conteúdos relacionados a armas CBRN.
-
Controles internos de segurança mais rígidos (como autenticação em dupla, segregação de acesso e monitoramento de exfiltração)
-
Restrições de acesso e vigilância reforçada no uso do modelo.
Por outro lado, se um determinado modelo de IA não possui capacidades perigosas (nível ASL-1), não há possibilidade de um adversário malicioso explorar tais capacidades (já elas não estão presentes), logo não é necessário investir em certos controles cuja implementação custa muito dinheiro. Este é o racional econômico por trás das avaliações de capacidades perigosas.
Dado que novas capacidades perigosas emergentes (ainda não previstas) podem surgir, tanto Anthropic quanto a OpenAI e a Google DeepMind enfatizam que suas respectivas frameworks estão sujeitas a evolução conforme aprendem mais.
Frontier Model Forun
O fato das grandes empresas de IA terem cada uma seu próprio framework para avaliar riscos parece um pouco preocupante. Não seria melhor se todas trabalhassem de forma mais alinhada, já que todas desenvolvem modelos avançados de IA? Este é o papel do Frontier Model Forum.
O Frontier Model Forum (FMF) é uma iniciativa conjunta criada em julho de 2023 pela Anthropic, Google DeepMind, Microsoft e OpenAI (a Amazon e a Meta se juntaram depois). O objetivo do FMF é promover o desenvolvimento seguro e responsável de modelos de IA altamente capazes —os chamados modelos de fronteira (frontier models).

Fonte da Imagem: Frontier Model Forum
Sendo um fórum colaborativo o FMF permite que empresas concorrentes:
-
Compartilhem boas práticas de avaliação de risco.
-
Definam quais capacidades perigosas devem ser monitoradas.
-
Desenvolvam em parceria padrões técnicos de segurança.
-
Avaliem quais riscos são globais (e portanto, demandam resposta coordenada).
-
Colaborem em pesquisas em alinhamento, Red Teaming e mitigação de riscos catastróficos.
-
Criem mecanismos de governança compartilhados para o uso seguro de modelos avançados.
Assim, embora cada empresa adote internamente seu próprio framework de gestão de riscos para avaliar os modelos de IA que criam, existe um certo alinhamento pois o FMF atua como um espaço que permite harmonizar princípios e discutir padrões globais, compartilhar boas práticas, técnicas de mitigação de riscos, e também (pelo menos em tese) colaborar com governos e sociedade civil na formulação de políticas públicas eficazes.
Importa ressaltar que o alinhamento das big techs que criam modelos de ponta com o Frontier Model Forum é voluntário e não vinculante por lei. Conforme destacado por análises externas, frameworks como o RSP da Anthropic e compromissos similares são políticas auto-impostas (autoregulação) – a empresa decide sozinha se está cumprindo os compromissos e pode alterar as regras a seu critério, sem penalidades formais exceto dano reputacional. Não é o lobo tomando conta das galinhas. É o lobo tomando conta de si próprio (as galinhas somos nós).
-
Por um lado, críticos apontam o risco de, se a corrida por modelos poderosos esquentar (com pressão comercial ou investidores), essas boas intenções serem “deixadas de lado quando mais importam”.
-
Por outro lado, as empresas argumentam que a transparência e cooperação atual criam um “race to the top” em segurança, onde nenhuma quer ficar atrás em confiabilidade. De fato, até agora vimos Anthropic, OpenAI e Google se desafiando mutuamente a implementar salvaguardas mais avançadas. Por exemplo, ao inaugurar o ASL-3, a Anthropic estabeleceu uma referência que pressiona as outras a terem proteção equivalente caso seus modelos cheguem no mesmo patamar.
De qualquer forma, já há no mercado modelos de IA muito poderosos que trazem grandes benefícios, mas também muitos riscos. Vamos fazer um resumo de alguns destes riscos.
Resumindo alguns dos riscos negativos da IA
Muitos dos riscos negativos da IA têm relação com a dificuldade de alinhar os objetivos passados para estes sistemas com os valores morais humanos, como discutido no "problema do Alinhamento de Valores". Segue um pequeno resumo das principais preocupações.
-
Discriminação - Há grande preocupação com a ocorrência de discriminação de determinados subgrupos sociais por causa de bias (vieses) em algoritmos usados em sistemas com IA. Além disso, a IA pode produzir decisões automatizadas com potencial de gerar impactos negativos e com efeitos de difícil reversão (por exemplo, negar de forma indevida auxílio a pessoas em vulnerabilidade social).
-
Confiabilidade - Há também riscos associados com a confiabilidade e uso seguro de soluções que utilizam inteligência artificial (por exemplo, os carros autônomos). Além da segurança no uso, a confiabilidade também tem relação com as predições feitas por sistemas de IA (por exemplo, erros em diagósticos médicos). Também é grande a preocupação com o uso militar da IA em armas autônomas como robôs e drones assassinos.
-
Cybersecurity - Há riscos relacionados com a segurança da informação. A IA pode ser utilizada em diferentes tipos de ataques cibernéticos contra infraestruturas críticas, e pode ela mesma (os sistemas de IA) ser alvo de tais ataques. Como já discutido, há temores de que no futuro em vez de apenas ser "utilizada" por agentes humanos em ataques cibernéticos (Misuse) a própria IA possa lançar ataques autônomos contra redes e infraestruturas críticas (Misalignment).
-
Manipulação social e riscos para as democracias - Após o episódio da Cambridge Analytica, aumenta em todo o mundo preocupação de que o uso de IA na moderação automática (filtragem) de conteúdo e também na propagação de desinformação e discursos de ódio possa afetar os resultados de eleições e erodir os sistemas democráticos, através da manipulação. Aqui também se enquadram os vídeos falsos (deep fake) e uso da IA para geração de fake news (conteúdo falso) em geral. Como evidenciado por eventos recentes aqui no Brasil (Musk desafiando o STF), as plataformas de mídias sociais (ex. X, Telegram) não são usualmente cooperativas com a justiça em escala global e não demonstram muita preocupação em fazer os investimentos necessários para evitar abusos, e em certos casos atuam ostensivamente contra a democracia, dado que lucram com o elevado volume de posts de desinformação e discursos de ódio.
-
Impactos ambientais - O processamento de alguns modelos de IA consome muita energia, e por tabela, pode gerar impactos para o meio ambiente. Este tema é estudado pelos especialistas em Green AI.
-
Automação de postos de trabalho - a questão do deslocamento de mão de obra também preocupa - em que medida as aplicações de AI vão substituir profissionais humanos, ou no mínimo, requerer sua requalificação? Os desafios abrangem entender quais serão as novas ocupações geradas pela IA, como capacitar as pessoas para trabalhar nelas, e quais profissões devem desaparecer. Nada disso é novidade, pois é característico da evolução tecnológica. Porém, dada a velocidade em que a AI está sendo adotada, este é um risco socioeconômico importante.
-
Monitoramento e vigilância social - O uso de IA no monitoramento civil por câmeras de segurança é uma outra preocupação em todo o mundo. Como extrair o benefício da tecnologia de reconhecimento facial, sem permitir o abuso destes sistemas por governos autoritários, ou mesmo por empregadores em ambientes de trabalho?
-
Desigualdade social e econômica - Sim, a IA tem enorme potencial para produzir valor na economia. Mas como este valor será dividido na sociedade? Se esta questão não for endereçada, a tendência (como já se viu muitas vezes no caso de outras inovações tecnológicas disruptivas) a tendência é que certos indivíduos e grupos econômicos (como as Big Techs) se tornem cada vez mais ricos, em detrimento de outros indivíduos, aumentando a já enorme desigualdade social que há no mundo.
-
Falta de inclusividade - Apesar da inclusividade ser um princípio importante, não é certo que os sistemas de IA serão adequadamente inclusivos e que seus benefícios poderão ser usufruídos por pessoas com diferentes tipos de deficiências. Em alguns casos, a dificuldade em acessar tais sistemas em contextos onde sua utilização seja mandatória (reconhecimento facial, biometria por voz etc.) poderá criar enormes dificuldades para estas pessoas no acesso a produtos e serviços.
-
Falta de transparência - É necessário que as soluções de AI tenham a devida transparência (interpretabilidade e
explanabilidade), para evitar a proliferação de soluções tipo “caixa preta”. Deve-se evitar que a lógica de operação e as decisões tomadas por tais sistemas (por exemplo, negar um empréstimo bancário) não sejam compreensíveis pelas partes afetadas. Uma questão relacionada com a transparência é a da responsabilização (accountability) - a possibilidade de se identificar e responsabilizar pessoas físicas ou jurídicas por eventuais danos causados pelo uso de soluções de AI.
A gravidade e a frequência de ocorrência de incidentes relacionados a estes riscos da IA podem ser medidas com benchmarks especializados, como HELM Safety e AIR-Bench”, como discutido em Governança da IA.
Riscos dos Agentes de IA
Agentes de Inteligência Artificial (IA) são sistemas baseados em IA projetados para perceber seu ambiente, tomar decisões autônomas e agir de forma a atingir objetivos específicos. Eles combinam técnicas de IA, como aprendizado de máquina, planejamento, raciocínio e interação natural (como linguagem), para atuar de maneira relativamente independente em tarefas complexas. Há diversos tipos de agentes de IA. Alguns podem ser simples, como um chatbot, ou bastante complexos, como sistemas que aprendem, se adaptam e interagem com o mundo físico ou digital, como veículos autônomos.
Os agentes de IA têm aplicação em diversos domínios, por exemplo:
-
Atendimento ao cliente: chatbots, voicebots, assistentes virtuais (por exemplo, suporte em serviços bancários)
-
Automação de tarefas corporativas: agentes que executam fluxos de trabalho (como o Microsoft Copilot)
-
Veículos autônomos: agentes que dirigem, planejam rotas, evitam obstáculos
-
Robótica: robôs com IA que realizam tarefas físicas ou colaborativas
-
Finanças: agentes programados para fazer análises de risco e negociação automática (trading bots)
-
Saúde: assistentes médicos, triagem de sintomas, apoio em diagnósticos, recomendação de condutas clínicas
-
Educação: tutores inteligentes, correção automatizada, aprendizado adaptativo
-
Segurança cibernética: agentes que detectam e reagem a ameaças em tempo real
Como se percebe, os agentes de IA trazem muitos benefícios, tais como:
-
Automatização de tarefas repetitivas e complexas
-
Eficiência e redução de custos operacionais
-
Personalização de experiências (recomendações, suporte)
-
Tomada de decisão baseada em dados em tempo real
-
Execução autônoma de tarefas 24/7
-
Adaptação a ambientes dinâmicos (aprendizado contínuo)
No domínio do uso de aplicações os agentes de IA marcam o início de uma nova camada de abstração sobre o SaaS tradicional — mais personalizada, mais proativa, e centrada em objetivos humanos, e não em cliques e interfaces. Por conta disso, Satya Nadella (CEO da Microsoft) alertou que estamos entrando em uma nova era onde o usuário não interage mais diretamente com o software tradicional, mas sim com agentes inteligentes que interagem com os softwares por nós. Por exemplo, em vez de abrir vários aplicativos (Word, Excel, PowerPoint, Teams), você interage com o Microsoft Copilot, e ele acessa essas ferramentas em segundo plano para realizar tarefas complexas por você — como escrever um relatório, gerar uma apresentação ou buscar dados de CRM. Um outro exemplo é o ChatGPT com plug-ins e agentes personalizados que podem realizar tarefas como reservas de vôos, programação, análises de dados etc.
Ou seja, o foco está no objetivo, e não na ferramenta: você diz "resuma esse relatório e me diga os principais insights", e o agente faz, sem você precisar abrir 3 ferramentas diferentes. Da mesma forma, os agentes permitem acesso unificado a dados e aplicativos - o agente pode acessar o seu e-mail, calendário, documentos — e relacionar informações automaticamente. Em certos cenários, o agente pode agir antes mesmo de ser solicitado (“Você tem uma reunião importante amanhã, aqui está um resumo do projeto discutido”).
Embora estejam revolucionando a forma como interagimos com sistemas computacionais, os agentes de IA também ampliam significativamente a superfície de risco, tanto em nível técnico quanto ético, operacional e de segurança. cibernética. Seguem alguns exemplos de riscos associados aos agentes de IA.
1. Risco de execução autônoma imprevisível - Agentes podem tomar decisões erradas ou inesperadas por conta de falhas nos dados de entrada (ex: instruções ambíguas), ou falta de alinhamento entre objetivos e ações, ou ainda por raciocínio incorreto em tarefas complexas de múltiplas etapas. Por exemplo, um agente pode tentar acessar recursos protegidos ou apagar arquivos achando que está “limpando” o ambiente.
2. Uso de agentes de IA para exploração maliciosa (AI-powered hacking) - Agentes de IA podem ser (e estão sendo!) utilizados para automatizar ataques de phishing personalizados com engenharia social, identificar vulnerabilidades em sistemas (ex: exploração de APIs) e automatizar ataque a contas com força bruta ou scraping de dados. Por exemplo, em 2023, pesquisadores do MIT e Stanford demonstraram como agentes baseados em LLMs, como AutoGPT, podiam ser instruídos a encontrar exploits públicos e usá-los para “hackear” simulações de servidores com sucesso, sem intervenção humana direta.
3. Perda de controle (loop de ações) - Agentes de IA com recurso de planejamento podem entrar em ciclos de ações inúteis ou perigosas, consumindo recursos computacionais excessivos (chamadas de API, dados, tempo de CPU). Também podem interagir com sistemas externos de forma inapropriada. Por exemplo, usuários do AutoGPT relataram que agentes entravam em loops infinitos, gerando e excluindo arquivos repetidamente, ou tentando executar tarefas com comandos ilegais.
4. Risco de alucinações em tarefas críticas - Os modelos de linguagem (LLMs) utilizados por agentes (como o ChatGPT, o Claude ou o Gemini) podem gerar informações falsas com alta confiança. Se o agente estiver sendo utilizado em tarefas de diagnóstico médico, análises de risco ou suporte legal, isso pode levar a erros graves. Por exemplo, em testes com agentes autônomos como o LangChain + GPT-4 com memória de contexto já foram observados “delírios de tarefa”, em que o agente “imaginava” arquivos ou dados que nunca foram fornecidos, e agia com base neles.
5. Problemas de privacidade e segurança de dados - Agentes de IA muitas vezes precisam acessar múltiplas fontes de dados pessoais ou corporativos (é o caso do Microsoft Copilot por exemplo). Se não forem bem controlados, podem vazar informações confidenciais. Por exemplo, uma falha inicial no plugin de navegação do ChatGPT expôs acidentalmente trechos de histórico de outros usuários. Agentes conectados a múltiplas APIs (por exemplo, Gmail + Google Drive) tornam este risco ainda maior. O acesso cruzado a serviços em nuvem (Google, Dropbox) com APIs internas (corporativas) também pode resultar em vazamentos acidentais.
6. Risco de manipulação e engenharia de Prompt - Adversários podem manipular os Prompts ou o ambiente onde são executados para que agentes se comportem de forma maliciosa (ataques de Prompt Injection). Pesquisadores da empresa Robust Intelligence demonstraram que um agente de IA projetado para análise financeira pôde ser induzido a executar comandos SQL deletando tabelas após receber uma instrução camuflada num campo de texto (Prompt Injection via metadados).
7. Responsabilidade legal indefinida - Quando um agente autônomo toma uma decisão errada, quem é o responsável? O programador do agente? O fornecedor do modelo (como a OpenAI)? A organização que integrou o agente em seus sistemas? Esta falta de clareza sobre responsabilização (accountability) é particularmente sensível em contextos como saúde, direito e finanças.
No ambiente corporativo, um desafio importante é o uso não supervisionado (Shadow AI), Funcionários podem utilizar ferramentas como o ChatGPT sem aprovação corporativa, aumentando riscos de vazamento de dados. É importante educar as equipes sobre os limites da IA e os perigos de plugins não autorizados.
A evolução dos agentes de IA exige equilíbrio entre inovação e gestão de riscos. Organizações que priorizam segurança, transparência e governança ética estarão melhor posicionadas para aproveitar o potencial da IA com menores riscoss de confidencialidade, integridade ou conformidade.
Riscos positivos (oportunidades)
Como conclusão, no outro lado da moeda é importante considerar as inúmeras oportunidades e benefícios que esta tecnologia traz. Seguem apenas alguns exemplos, como contrapontos para riscos negativos associados com a própria IA.
O recado é que não se deve ser maniqueísta em relação à Inteligência Artificial, assim como em relação ao uso da eletricidade por exemplo - ambas as tecnologias podem ser utilizadas de forma adequada ou inadequada, em boa ou em má fé, e não são intrinsicamente "boas" ou "más". O importante é o uso que nós, humanos, fazemos delas.

-
A IA pode ser utilizada para espalhar fake news, manipulação e discursos de ódio e assim atacar pessoas e instituições para erodir as bases da democracia, mas também pode facilitar e ampliar a participação popular em debates, possibilitando maior representatividade nas deliberações para grupos que em geral são excluídos, e desta forma contribuir para o fortalecimento dos sistemas democráticos. Além disso, a própria IA pode ser utiizada para detectar fake news e deep fakes e alertar ou conter a disseminação de notícias falsas impulsionadas em redes sociais, além de outros conteúdos inapropriados (por exemplo, pornografia ilegal).
-
A IA pode produzir discriminação em processos de seleção de pessoal por conta de vieses nos algoritmos, mas também pode apoiar de formas positivas os processos de contratação nas empresas.
-
A IA pode agravar desigualdades econômicas, mas também pode ser utilizada para aumentar a produtividade na indústria, no agronegócio, nos serviços públicos e em diversos outros domínios, e assim contribuir para a melhoria da economia.
-
A IA pode ser utilizada para realizar ataques cibernéticos, mas também pode ajudar na defesa cibernética (cybersecurity) de organizações e países.
-
A IA pode gerar impactos ambientais (associados por exemplo ao consumo de água (para restriamento) e de energia nos data centers que hospedam os recursos computacionais utilizados para treinar grandes modelos de linguagem e hospedam sistemas de IA), mas por outro lado a inteligência artificial também pode ser utilizada em muitos projetos que contribuem para a sustentabilidade, em favor da natureza. Além disso a IA pode ajudar na prevenção de desastres climáticos, na otimização da gestão de resídios e reciclagem, na detecção de desmatamento ilegal através de monitoração por satélites e em muitos outros contextos.
-
A IA pode gerar deslocamento de mão-de-obra e desemprego, mas em muitos casos os sistemas de IA vão complementar (e não substituir) o trabalho humano atuando como auxiliares (como já se vê em escala global com o uso de assistentes como o ChatGPT e o Copilot), aumentando sua eficiência e produtividade. Além disso, novas profissões devem surgir e outras terão grande demanda (por exemplo, pilotos de drone, especialistas em robótica, cientistas de dados, desenvolvedores de modelos de IA preditiva e generativa, especialistas em realidade aumentada etc.), embora em muitos destes casos o nível de qualificação requerido tenda a ser elevado.
Referências selecionadas
AI Frontiers - Dan Hendrycks and Laura Hiscott
Apr 22, 2025
Último acesso em 11/08/2025
Maksym Andriushchenko et al
Apr 18, 2025
Último acesso em 11/08/2025
AI Frontiers - Andy Zou and Jason Hausenloy
Apr 9, 2025
Último acesso em 11/08/2025
AI Frontiers
Apr 9, 2025
Último acesso em 11/08/2025
Google DeepMind - Rohin Shah et al
2 April 2025
Último acesso em 11/08/2025
Google Threat Intelligence Group
January 29, 2025
Último acesso em 11/08/2025
AI ACTION SUMMIT
January 2025
Último acesso em 11/08/2025
NIST (National Institute of Standards and Technology)
July 2024
Último acesso em 11/08/2025
NIST (National Institute of Standards and Technology)
July 2024
Último acesso em 11/08/2025
INDEPENDENT - Andrew Griffin
20 May 2024
Último acesso em 11/08/2025
OpenAI - Yonadav Shavit et al
Dec 2023
Último acesso em 11/08/2025
ONU (United Nations University)
24 Jul 2023
Último acesso em 11/08/2025
Elizabeth M. Renieris et al
June 20, 2023
Último acesso em 11/08/2025
Vladislav Tushkanov
15 Maio 2023
Último acesso em 11/08/2025
Victor Hugo Silva, G1
2 Maio 2023
Último acesso em 11/08/2025
Cezary Gesikowski
25 February 2023
Último acesso em 11/08/2025
Stuart Russell (article on autonomous weapons - Nature)
21 February 2023
Último acesso em 11/08/2025
U.S. Department of State
FEBRUARY 16, 2023
Último acesso em 11/08/2025
Robert Lemos
October 20, 2021
Último acesso em 11/08/2025
Shanthi Lekkala et al
10 Sep 2021
Último acesso em 11/08/2025
Edson Kaique Lima - Olhar Digital
18 de Maio, 2021
Último acesso em 11/08/2025
Amanpour and Company
May 9, 2021
Último acesso em 11/08/2025
Camila Domonoske - NPR
July 17, 2017
Último acesso em 11/08/2025
Veja também